html2canvas 源码解读
前言
html2canvas库主要使用的是 Canvas 实现方式,主要过程是手动将 dom 重新绘制成 canvas,并没有截取页面的屏幕截图,而是根据从 DOM 读取的属性构建页面的表示,因此,它只能正确渲染可以理解的属性,有许多 CSS 属性无法正确渲染。
暂时不支持渲染的 CSS 属性
- background-blend-mode
- border-image
- box-decoration-break
- box-shadow
- filter
- font-variant-ligatures
- mix-blend-mode
- object-fit
- repeating-linear-gradient()
- writing-mode
- zoom
使用
html2canvas对外暴露了一个可执行函数,它的第一个参数用于接收待绘制的目标节点(必选);第二个参数是可选的配置项,用于设置涉及 canvas 导出的各个参数:
options 对象可选的值
| Name | Default | Description |
|---|---|---|
| allowTaint | false | 是否允许跨域图像污染画布 |
| backgroundColor | #ffffff | 画布背景颜色,如果在 DOM 中没有指定,设置“null”(透明) |
| canvas | null | 使用现有的“画布”元素,用来作为绘图的基础 |
| foreignObjectRendering | false | 是否使用 ForeignObject 渲染(如果浏览器支持的话) |
| imageTimeout | 15000 | 加载图像的超时时间(毫秒),设置为“0”以禁用超时 |
| ignoreElements | (element) => false | 从呈现中移除匹配元素 |
| logging | true | 为调试目的启用日志记录 |
| onclone | null | 回调函数,当文档被克隆以呈现时调用,可以用来修改将要呈现的内容,而不影响原始源文档。 |
| proxy | null | 用来加载跨域图片的代理 URL,如果设置为空(默认),跨域图片将不会被加载 |
| removeContainer | true | 是否清除 html2canvas 临时创建的克隆 DOM 元素 |
| scale | window.devicePixelRatio | 用于渲染的缩放比例,默认为浏览器设备像素比 |
| useCORS | false | 是否尝试使用 CORS 从服务器加载图像 |
| width | Element width | canvas 的宽度 |
| height | Element height | canvas 的高度 |
| x | Element x-offset | canvas 的 x 轴位置 |
| y | Element y-offset | canvas 的 y 轴位置 |
| scrollX | Element scrollX | 渲染元素时使用的 x 轴位置(例如,如果元素使用 position: fixed) |
| scrollY | Element scrollY | 渲染元素时使用的 y 轴位置(例如,如果元素使用 position: fixed) |
| windowWidth | Window.innerWidth | 渲染元素时使用的窗口宽度,这可能会影响诸如媒体查询之类的事情 |
| windowHeight | Window.innerHeight | 渲染元素时使用的窗口高度,这可能会影响诸如媒体查询之类的事情 |
语法:
// element 为目标绘制节点,options为可选参数
html2canvas(element[,options]);
调用示例:
import html2canvas from 'html2canvas'
const options = {}
// 输入dom节点,返回包含dom视图内容的canvas对象
html2canvas(dom, options).then(function (canvas) {
document.body.appendChild(canvas)
})
浏览器支持情况
TIP
- Firefox 3.5+
- Google Chrome
- Opera 12+
- IE9+
- Safari 6+
原理分析
html2canvas 的基本原理是读取 DOM 元素的信息,基于这些信息去构建截图,并呈现在 canvas 画布中。其中重点就在于将 dom 重新绘制成 canvas 的过程,该过程整体的思路是:
遍历目标节点和目标节点的子节点,遍历过程中记录所有节点的结构、内容和样式,然后计算节点本身的层级关系,最后根据不同的优先级绘制到 canvas 画布中。
html2canvas 的解析过程:
构建配置项 在这一步会结合传入的 options 和一些 defaultOptions,生成用于渲染的配置数据 renderOptions。相关配置的分类如下:
jsresourceOptions:资源跨域相关配置 contextOptions:缓存、日志相关配置 windowOptions:窗口宽高、滚动配置 cloneOptions:对指定dom的配置 renderOptions:render结果的相关配置,包括生成图片的各种属性clone 目标节点并获取样式和内容
解析目标节点
目标节点的样式和内容都获取到了之后,就需要把它所承载的数据信息转化为 Canvas 可以使用的数据类型。在对目标节点的解析方法中,递归整个 DOM 树,并取得每一层节点的数据,对于每一个节点而言需要绘制的部分包括边框、背景、阴影、内容,而对于内容就包含图片、文字、视频等。在整个解析过程中,对目标节点的所有属性进行解析构造,转化成为指定的数据格式,基础数据格式可见以下代码:
class ElementContainer {
// 所有节点上的样式经过转换计算之后的信息
readonly styles: CSSParsedDeclaration;
// 节点的文本节点信息, 包括文本内容和其他属性
readonly textNodes: TextContainer[] = [];
// 当前节点的子节点
readonly elements: ElementContainer[] = [];
// 当前节点的位置信息(宽/高、横/纵坐标)
bounds: Bounds;
// 用来决定如何渲染的标志
flags = 0;
...
}
构建内部渲染器
把目标节点处理成特定的数据结构之后,就需要结合 Canvas 调用渲染方法了,Canvas 绘图需要根据样式计算哪些元素应该绘制在上层,哪些在下层,那么这个规则是什么样的呢?这里就涉及到 CSS 布局相关的一些知识。默认情况下,CSS 是流式布局的,元素与元素之间不会重叠。不过有些情况下,这种流式布局会被打破,比如使用了浮动(float)和定位(position)。因此需要识别出哪些脱离了正常文档流的元素,并记住它们的层叠信息,以便正确地渲染它们。那些脱离正常文档流的元素会形成一个层叠上下文。
层叠上下文和层叠顺序的规则:
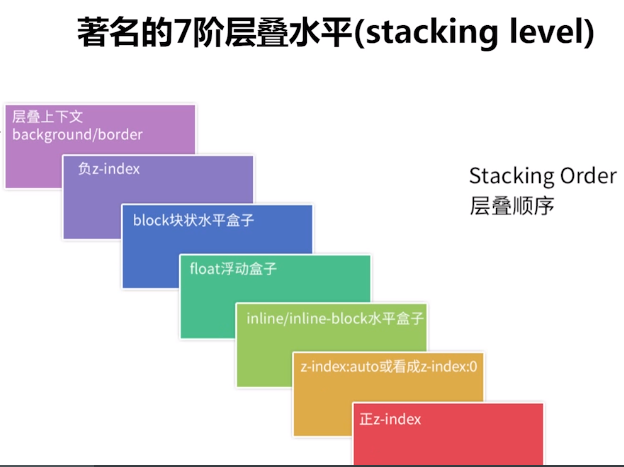
绘制数据 调用
renderStackContent方法,将 DOM 元素一层一层渲染到 canvas 中。
html2canvas转换为图片使用了两种方式,一种是将 DOM 转换为 canvas 再转换为图片,另一种是通过设置配置项 foreignObjectRendering 为 true(如果浏览器支持的话),将 DOM 转换为 svg 再转换为图片.
源码分析
入口方法
const html2canvas = (
element: HTMLElement,
options: Partial<Options> = {}
): Promise<HTMLCanvasElement> => {
return renderElement(element, options)
}
入口方法返回的是renderElement调用的结果,因此直接看renderElement方法。
renderElement方法的主要目的是将页面中指定的 DOM 元素渲染到一个 canvas 中,并将渲染好的 canvas 返回给用户。
renderElement方法主要做的事情:
- 构建配置项,解析用户传入的 options,将其与默认的 options 合并,得到用于渲染的配置数据 renderOptions。
- 获取 DOM 节点信息,对传入的 DOM 元素进行解析,取到节点信息和样式信息,这些节点信息会和上一步的 renderOptions 配置一起传给
canvasRenderer实例,用来绘制 canvas。 canvasRenderer将依据浏览器渲染层叠内容的规则,将用户传入的 DOM 元素渲染到一个 canvas 中。
renderElement方法的核心代码如下:
const renderElement = async (
element: HTMLElement,
opts: Partial<Options>
): Promise<HTMLCanvasElement> => {
const renderOptions = { ...defaultOptions, ...opts } // 合并默认配置和用户配置
if (foreignObjectRendering) {
// foreignObject渲染
const renderer = new ForeignObjectRenderer(context, renderOptions)
return await renderer.render(clonedElement)
} else {
// canvas渲染
const root = parseTree(clonedElement) // 解析用户传入的DOM元素(为了不影响原始的DOM,实际上会克隆一个新的DOM元素),获取节点信息
const renderer = new CanvasRenderer(renderOptions) // 根据渲染的配置数据生成canvasRenderer实例
return await renderer.render(root) // canvasRenderer实例会根据解析到的节点信息,依据浏览器渲染层叠内容的规则,将DOM元素内容渲染到canvas中
}
}
parseTree 解析节点信息
const parseTree = (context: Context, element: HTMLElement): ElementContainer => {
// 根据不同的元素创建不同的ElementContainer获取元素节点信息
const container = createContainer(context, element)
// 用来决定如何渲染的标志
container.flags |= FLAGS.CREATES_REAL_STACKING_CONTEXT
// 递归dom元素解析节点信息
parseNodeTree(context, element, container, container)
return container
}
parseTree 的入参是一个普通的 DOM 元素,根据不同的元素,返回对应的ElementContainer对象。共有以下几类:
- image(ImageElementContainer)
- canvas (CanvasElementContainer)
- svg (SVGElementContainer)
- li (LIElementContainer)
- ol (OLElementContainer)
- input (InputElementContainer)
- select (SelectElementContainer)
- textarea (TextareaElementContainer)
- iframe (IFrameElementContainer)
- 其他类型(ElementContainer)
对于ElementContainer 对象获取的信息:
- bounds:位置信息(width|height|left|top)
- textNodes:文本节点
- elements:子元素信息
- flags:用来决定如何渲染的标志
- styles:样式
ImageElementContainer对象获取的信息:
- src:图片地址
- intrinsicWidth:图片宽度
- intrinsicHeight : 图片高度
CanvasElementContainer对象获取的信息:
- canvas:canvas 元素
- intrinsicWidth:canvas 宽度
- intrinsicHeight : canvas 高度
SVGElementContainer对象获取的信息:
- svg: svg 元素
- intrinsicWidth: 元素宽度
- intrinsicHeight : 元素高度
isLIElement对象获取的信息:
- value: 元素内容
isOLElement对象获取的信息:
- start: ol 列表的 type 属性值
- reversed: 列表顺序反转
isInputElement对象获取的信息:
- svg: svg 元素
- intrinsicWidth: 元素宽度
- intrinsicHeight : 元素高度
isSelectElement对象获取的信息:
- type: 元素类型(单选框或复选框)
- checked: 元素是否选中
- value : 元素值
isTextareaElement对象获取的信息:
- value: 元素内容
isIFrameElement对象获取的信息:
- src: 规定在 iframe 中显示的文档的 URL
- width: iframe 宽度
- height : iframe 高度
- tree:element 元素
- backgroundColor:背景颜色
对于 iframe 的解析,首先解析 iframe,对于 iframe 内的 dom 元素再次调用 parseTree 解析。
该对象包含的只是节点树的相关信息,不包含层叠数据,层叠数据在 parseStackingContexts 方法中取得。
renderer.render
有了节点信息就可以构建渲染器,渲染的逻辑如下:
- 使用上一步解析到的节点数据,生成层叠数据
- 使用节点的层叠数据,依据浏览器渲染层叠数据的规则,将 DOM 元素一层一层渲染到离屏 canvas 中 render 核心代码如下:
async render(element: ElementContainer): Promise<HTMLCanvasElement> {
// 解析层叠信息
const stack = parseStackingContexts(element);
// 渲染层叠内容
await this.renderStack(stack);
return this.canvas;
}
parseStackingContexts
parseStackingContexts解析层叠信息的方式和parseTree解析节点信息的方式类似,都是递归整棵树,收集树的每一层的信息,形成一颗包含层叠信息的层叠树。
const parseStackingContexts = (container: ElementContainer): StackingContext => {
// 解析层叠信息
const paintContainer = new ElementPaint(container, null)
// 生成指定的层叠数据
const root = new StackingContext(paintContainer)
const listItems: ElementPaint[] = []
parseStackTree(paintContainer, root, root, listItems)
processListItems(paintContainer.container, listItems)
return root
}
层叠数据结构如下:
// 当前元素
element: ElementPaint
// z-index 为负, 形成层叠上下文
negativeZIndex: StackingContext[];
// z-index 为 0、auto、transform 或 opacity, 形成层叠上下文
zeroOrAutoZIndexOrTransformedOrOpacity: StackingContext[];
// 定位和 z-index 形成的层叠上下文
positiveZIndex: StackingContext[];
// 没有定位和 float 形成的层叠上下文
nonPositionedFloats: StackingContext[];
// 没有定位和内联形成的层叠上下文
nonPositionedInlineLevel: StackingContext[];
// 内联节点
inlineLevel: ElementPaint[];
// 不是内联的节点
nonInlineLevel: ElementPaint[];
而渲染层叠内容的renderStack方式实际上调用的是renderStackContent方法,该方法是整个渲染流程中最为关键的方法。
renderStackContent
renderStackContent主要做的是将 DOM 元素一层一层的渲染到离屏 canvas 中。默认情况下,CSS 是流式布局的,元素与元素之间不会重叠。不过有些情况下,这种流式布局会被打破,比如使用了浮动(float)和定位(position),那些脱离正常文档流的元素会形成一个层叠上下文,因此需要根据层叠上下文规则进行渲染,renderStackContent就是对 CSS 层叠布局规则的一个实现:
async renderStackContent(stack: StackingContext) {
// 1. 最底层是background/border
await this.renderNodeBackgroundAndBorders(stack.element);
// 2. 第二层是负z-index
for (const child of stack.negativeZIndex) {
await this.renderStack(child);
}
// 3. 第三层是block块状盒子
await this.renderNodeContent(stack.element);
for (const child of stack.nonInlineLevel) {
await this.renderNode(child);
}
// 4. 第四层是float浮动盒子
for (const child of stack.nonPositionedFloats) {
await this.renderStack(child);
}
// 5. 第五层是inline/inline-block水平盒子
for (const child of stack.nonPositionedInlineLevel) {
await this.renderStack(child);
}
for (const child of stack.inlineLevel) {
await this.renderNode(child);
}
// 6. 第六层是以下三种:
// (1) ‘z-index: auto’或‘z-index: 0’。
// (2) ‘transform: none’
// (3) opacity小于1
for (const child of stack.zeroOrAutoZIndexOrTransformedOrOpacity) {
await this.renderStack(child);
}
// 7. 第七层是正z-index
for (const child of stack.positiveZIndex) {
await this.renderStack(child);
}
}
foreignObject 渲染
foreignObject 渲染就是根据渲染的配置数据生成 ForeignObjectRenderer 实例,然后调用实例的 render 方法,返回 canvas.
async render(element: HTMLElement): Promise<HTMLCanvasElement> {
// 将node节点通过foreignObject包裹转换为svg
const svg = createForeignObjectSVG(
this.options.width * this.options.scale,
this.options.height * this.options.scale,
this.options.scale,
this.options.scale,
element
);
// 将node节点通过 XMLSerializer().serializeToString() 序列化为字符串
const img = await loadSerializedSVG(svg);
this.ctx.drawImage(img, -this.options.x * this.options.scale, -this.options.y * this.options.scale);
return this.canvas;
}
createForeignObjectSVG
createForeignObjectSVG方法主要就是将 node 节点通过 foreignObject 包裹转换为 svg
const createForeignObjectSVG = (
width: number,
height: number,
x: number,
y: number,
node: Node
): SVGForeignObjectElement => {
const xmlns = 'http://www.w3.org/2000/svg'
const svg = document.createElementNS(xmlns, 'svg')
const foreignObject = document.createElementNS(xmlns, 'foreignObject')
svg.setAttributeNS(null, 'width', width.toString())
svg.setAttributeNS(null, 'height', height.toString())
foreignObject.setAttributeNS(null, 'width', '100%')
foreignObject.setAttributeNS(null, 'height', '100%')
foreignObject.setAttributeNS(null, 'x', x.toString())
foreignObject.setAttributeNS(null, 'y', y.toString())
foreignObject.setAttributeNS(null, 'externalResourcesRequired', 'true')
svg.appendChild(foreignObject)
foreignObject.appendChild(node)
return svg
}